SECURE CLOUD TRANSFORMATION
THE CIO'S JOURNEY
By Richard Stiennon
Introduction Section 1: Transformation Journey Chapter 1: Mega-Trends Drive Digital Transformation Chapter 2: Moving Applications to the Cloud Chapter 3: From Hub-and-Spoke to Hybrid Networks Chapter 4: Security Transformation Section 2: Practical Considerations Chapter 5: Successfully Deploying Office 365 Chapter 6: A Reference Architecture for Secure Cloud Transformation Chapter 7: Perspectives of Leading Cloud Providers Section 3: The CIO Mandate Chapter 8: The Role of the CIO is Evolving Chapter 9: CIO Journeys Section 4: Getting Started Chapter 10: Creating Business Value Chapter 11: Begin Your Transformation Journey Appendix Contributor Bios Author Bio Read Offline: Open All Chapters in Tabs eBookChapter 4
Security Transformation

“Security is an obvious priority. Without it, the rest of cloud transformation cannot happen.”
Hervé Coureil, Chief Digital Office, Schneider Electric

Traditional security approaches focused on establishing a perimeter around the corporate network
For over 30 years, IT security focused on protecting an organization by establishing a perimeter to secure the corporate network. This approach was based on the premise that all enterprise users, data, and applications resided on the corporate network. To meet the requirements of this approach, organizations deployed a “castle-and-moat” security approach where the corporate network was the “castle” that was surrounded by a “moat” of security appliances. To allow traffic in and out of the “castle,” organizations created internet gateways that provide a drawbridge across the “moat.” These gateways initially consisted of a network firewall to establish a physical perimeter separating the internet from users, data, and applications.
As internet traffic increased and cyber attacks became more sophisticated, the “moat” was expanded to include new appliances to form an outbound gateway to enable users to access the internet. This gateway, or DMZ (Demilitarized Zone), was comprised of URL filtering, anti-virus, data loss prevention, and sandbox appliances. In addition to outbound internet gateways, organizations introduced inbound gateways to bring remote users into the corporate network. Inbound gateways generally consist of load balancers, DDoS (Distributed Denial of Service) protection, firewalls, and VPN concentrators. Under the legacy approach, internet and VPN traffic must pass through a DMZ consisting of multiple appliances.
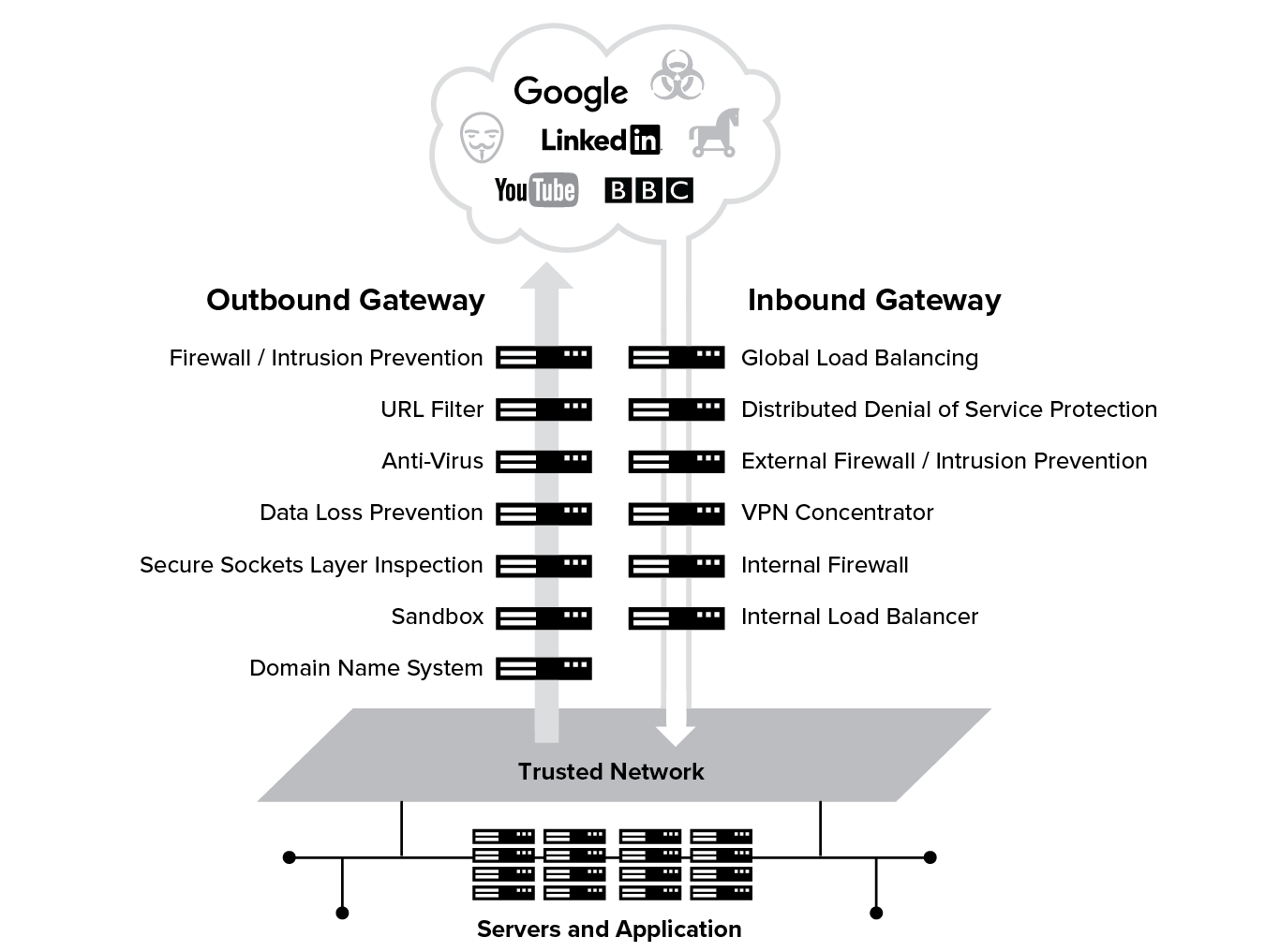
Evaluating Castle-and-Moat in the Cloud Era
Your security transformation journey starts with looking at how your castle-and-moat security architecture is run. When users are mobile, working remotely or in branch offices, and the applications they use are in the cloud, routing traffic back across a “hub-and-spoke” network to the data center for access and security controls provides a poor user experience. To deliver a fast user experience, traffic needs to be routed directly to the internet. Routing traffic directly to the internet, while maintaining access and security controls, may require deployment of hundreds, if not thousands, of internet gateways, which would be prohibitively expensive to purchase, deploy, and manage. These appliances are not elastic in nature, as is the case with cloud-native solutions, and tend to have different capabilities at different scales. As such, a solution deployed on premises in the data center will not translate identically for a 100-person branch implementation.
The traditional security model of hub-and-spoke makes the adoption of cloud and mobility extremely costly and cumbersome. It results in organizations having to make decisions that lead to significant tradeoffs:
- Cost and Complexity: To maintain a certain level of security and user experience, you will need to deploy top-of-the-line appliances to the hundreds of branches and ensure that they are all kept in sync on policy. Deploying, integrating, and maintaining these gateways, each of which is a collection of heterogeneous network and security appliances with separate management and reporting systems, is resource intensive and complex to manage. This complexity leads to reduced reliability of the networking and security infrastructure.
- Security tradeoffs: To keep cost and complexity in check, you will be forced to deploy gear in branches that is less sophisticated than what you have in your data center, and this leads to reduced security efficacy. As the majority of internet traffic is now encrypted, this tradeoff is increasingly risky as organizations often do not have or do not utilize SSL decryption on their appliances and are therefore blind to a large proportion of their traffic. In addition, security appliances come from a heterogeneous array of vendors and are not designed to share threat information, leading to a severe limitation in the level of threat detection and prevention.
- Poor user experience: Backhauling traffic through these traditional dedicated Wide Area Network, or WAN, techniques, such as MPLS or leased lines and the serial processing of traffic by network security appliances introduces latency that results in a poor user experience.
In general, applying old security paradigms to a digital enterprise forces the organization to make trade offs. The situation is made even more complex due to the evolving threat landscape as we’ll highlight next.
Evolving Threat Landscape
Risks to cybersecurity represent a growing trend for the modern enterprise. Threats are not only more prevalent, they are more impactful, and threat actors grow more sophisticated with their methods of attack. Corporate data breaches are increasing in numbers and a topic of conversation in every board meeting. As such, the tools the cyber security teams use must evolve as the threat actors and threat vectors have evolved.
While security infrastructure has remained static in a state of staid intransigence, malware has evolved:
- As SSL spreads, so does encrypted malware: More than 70% of internet traffic is now SSL-delivered, and that percentage will climb.4 That’s a good thing. Such encryption exploits are growing: Over the course of 2017, SSL-encoded malware attacks increased more than 30%.5 With the coming industry standardization of TLS 1.3, traditional forensic-analysis scanning techniques like packet capture will cease to be effective. With nearly all traffic SSL-delivered, next-generation firewalls will no longer effectively protect corporate networks.
- Credentials are more easily stolen or corrupted: Controlling identity is the first line of defense for any corporation in the cloud era. However, most organizations have many identity stores making it easy for hackers to compromise employee identity without knowledge. Complicating matters further, access is often extended to contractors or offsite workers. Keeping identity data current becomes harder when accounts go stale. Furthermore, social-engineering hackers pose a significant threat as they exploit human nature to get at critical corporate assets.
- BYOD keeps employees happy but opens doors for hackers: Enterprises must accommodate network access for mobile devices. If those devices are not necessarily company-issued, it’s difficult to ensure appropriate device security posture: Many high-profile security breaches and viruses (notably, CryptoLocker) spread laterally after infected devices are brought onto the corporate network.
- Threats are self-morphing and rapidly evolving: The now-famous APT1 report, named for an advanced persistent threat team and which described for the first time a concerted hacking campaign emanating from China, kicked off the shift to so-called breach detection and response.6 The most recent scourge to appear is ransomware and many organizations have succumbed to debilitating attacks from NotPetya and WannaCry. Today, there can be 100 variants of a new strain of ransomware appearing overnight.
- Trusted networks lead to lateral attacks: The modern enterprise cannot secure itself without assuming its walls have already been breached. Attackers these days go to great lengths to ensure they can laterally proliferate an organization in a stealthy manner. Without segmentation and continuously monitoring traffic between employees and applications, and between server-to-server, the enterprise is blind to its threat posture being compromised.
Securing the modern enterprise with a cloud security ecosystem
The key to securing the modern enterprise is to focus directly on securing the data, and much less on securing the network that it resides on. In a world where the organization relies on multiple data center providers, multiple cloud providers, multiple network providers, and to a variety of end computing devices, the data security model starts with classification and appropriate risk treatment and risk acceptance. A new security ecosystem is required to protect enterprise data.
Data Classification and Responsibilities
The transition to a cloud security ecosystem will require organizations to think through the responsibility matrix of their data security needs to determine what can be controlled by the organization and what can be taken as SLAs from their providers.
To secure enterprise data in this new paradigm, one has to classify applications into two basic types: externally-managed and internally-managed. A parallel is looking at managed versus unmanaged user devices.
Two basic types of applications:
- Externally-managed: These are internet destinations or SaaS applications that have their own data security mechanisms that you can neither control nor dictate. Some examples of these are applications such as CNN, Box, and Salesforce.
- Internally-managed: These are applications that are hosted in your data center or your IaaS provider for which you ensure data security. Examples of these are an SAP application in your data center, or an employee portal hosted in your AWS instance.
In the legacy world, applications were managed internally, and as such all the responsibility for running, managing, and securing these applications was within the realm of the enterprise. This model, however, fractures when deploying in the cloud. In the new world you enter into a shared responsibility model. For example, with externally managed applications such as Salesforce, you cannot run your own firewall in front of it, nor can you run your own malware engine. In the cloud, you have to create a solution that can augment those services provided by the vendors, with the right levels of control to ensure that the organization leveraged the cloud securely.7

Blueprint for a Cloud Security Ecosystem
Figure 4.2 illustrates an architecture blueprint for a cloud security ecosystem. This ecosystem has to provide all the same functions previously available in the data center, but in a form factor that is no longer tethered to a network.
In the cloud, you don’t have a “trusted network” as defined in the on-premises world anymore. Threat assessment and mitigation now have to be done continuously, at different levels, and in real-time. Neil MacDonald from Gartner defines this framework as CARTA (Continuously Assessed Risk/Trust and Adapting).8 Identity, context-aware policy, and continuous monitoring are the key pillars to Gartner’s CARTA and of the cloud security blueprint of the future.
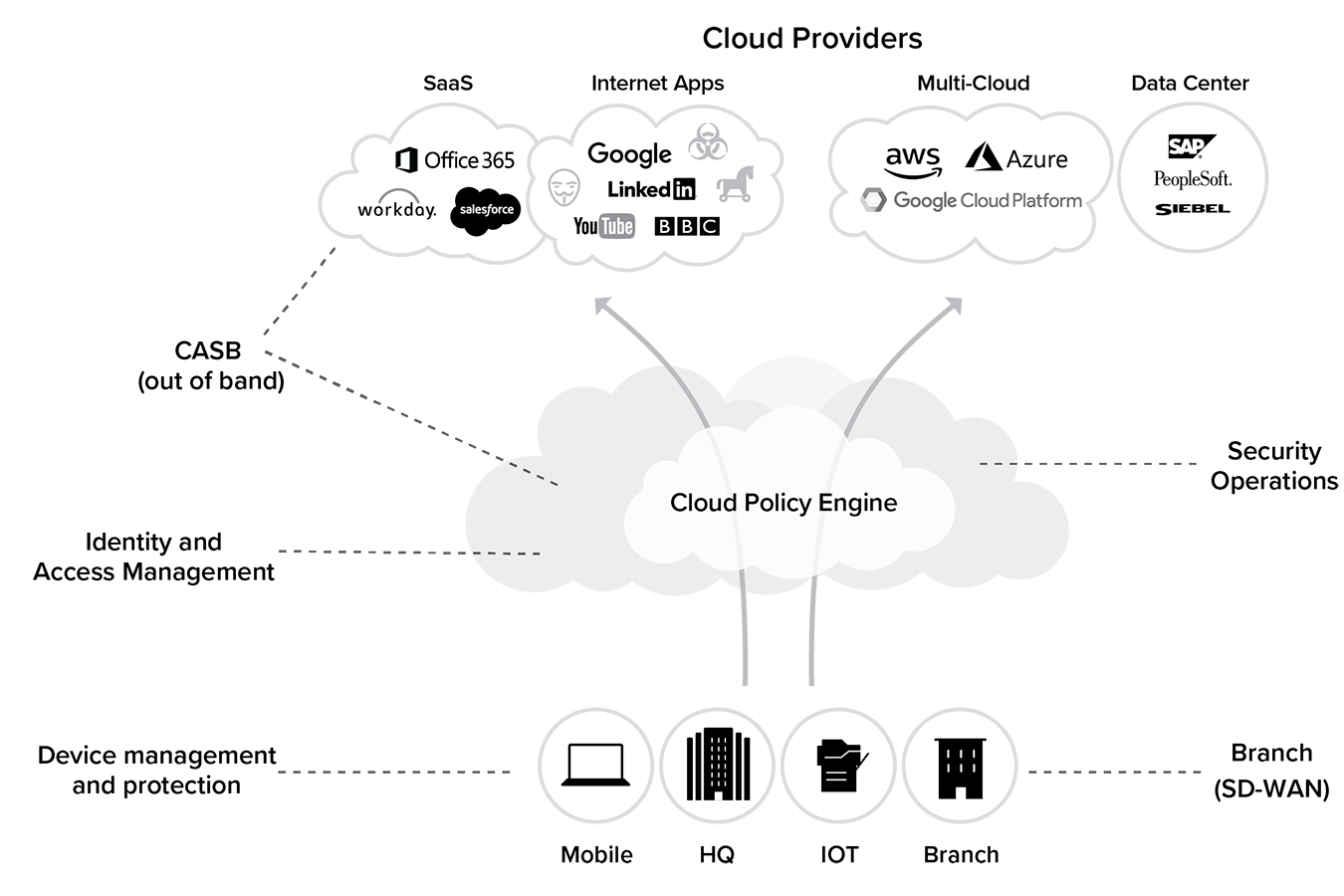
The following components represent some key requirements of a cloud security ecosystem:
1. Identity and Access Management
As you move to the cloud, defining “trust” parameters and establishing identity are crucial. This critical component becomes the starting point for any secure cloud transformation journey. Having a single aggregation point for federating identity to all applications becomes the first line of defense. The identity management system must be able to provide multi-factor authentication, step-up authentication, and adaptive authentication capabilities. Identity providers can detect potentially malicious or harmful activity based on deviations from the norm. Ideally the identity system is not only providing authentication, but also entitlement and authorization for the use of resources. Authorization is typically done by policy on the gateway. However, this can result in misconfigurations. The application, as well as the access gateway, should feed on the same assertion from the identity provider as the single source of truth. This ensures there are no mismatched firewall rules or orphaned rule lines in the firewall as people, organizations, and roles change over time. The identity provider must become the single point for all permission management.
2. Cloud Policy Engine
The foundation of a cloud security ecosystem is the cloud policy engine that is located at the intersection of all types of network flows—from managed to unmanaged devices and locations, to externally or internally managed clouds. This engine must seamlessly interface with the identity management, software-defined WAN, device management tools, and SOC (Security Operations Center) solutions.
It must be optimally located near the shortest path between the user and the application, and once identity and authorization are established, the connection between the user and the application must be continuously inspected by it. Most identity providers can signal changes in real-time with SCIM (System for Cross-domain Identity Management) if a risk profile changes. The network must be able to take action immediately on the new risk, even on existing sessions.
There are two types of functions the engine must provide depending on whether the destination is internally or externally managed. For externally managed applications, the gateway must provide a complete security inspection stack with capabilities to detect malicious threats using SSL interception, deep packet inspection, IPS, zero-day vulnerability shielding, sandboxing, and machine learning. The engine must also provide full inline data loss prevention to ensure data boundaries as defined by the compliance team can be maintained.
For internally managed applications, this policy engine must ensure that the right user or device is getting connected to the right application without exposing your application/server network to the user. Since the policy engine front ends all application access, it must also subsume functions such as local and global load-balancing for continuous availability, and defend against denial of service attacks.
There are several common characteristics that this cloud policy engine must satisfy for this architecture to be effective:
1. It must integrate seamlessly with the identity and entitlement system. For example, it should be able to accept SAML-based authentication and entitlement like your applications do.
2. It must provide the same capabilities regardless of the user location or device type, as well as the location of the destination application. For example, a branch with five people, an employee at home on an Android phone, and those at the corporate headquarters must have the same (not just similar) security enforcement and user experience capabilities.
3. It must ubiquitously serve all application destinations. For example, the cloud policy engine must be well connected to all clouds, be it AWS, Azure, or Salesforce clouds.
4. It must integrate seamlessly with the existing SOC, governance, and remediation functions. For example, the SOC should have complete visibility within the logging and monitoring systems and be able to complete remediation workflows within its existing toolchains.
3. Security Operations Center (SOC)
The role of a SOC is ever more critical in a cloud-first world, providing a fast path to build and extend your proactive threat hunting capabilities. Unlike the on-premise world where the scope of monitoring the data center was limited to having control and visibility of the data alone, in the cloud, user and device mobility compounded by a complex and evolving threat environment require a much more sophisticated approach.
Organizations must always assume the posture of being compromised and ensure they have continuous, real-time visibility of all activities on the network, the endpoints, and their cloud applications in place. This requires integrating logs from all relevant inputs and correlating them with internal and external threat intelligence to ensure that any breach is detected and curtailed in the shortest time possible.
However, due to the amount of data that traverses the enterprise today, it is crucial to have tools in place that summarize the organizational risk by automatically classifying incidents and events into priorities for the SOC to follow up.
4. Cloud Access Security Broker (CASB)
In the legacy world, organizations deployed tools such as RSA Archer to ensure access controls were correctly set up and regularly audited. There were also malware inspection engines running on the application host itself, and protections such as web application firewalls (WAF) to prevent application level attacks.
With SaaS applications, these controls must be augmented through a CASB platform. Gartner defines a CASB as security policy enforcement points placed between cloud service consumers and cloud service providers to combine and interject enterprise security policies as the cloud-based resources are accessed.9 CASBs consolidate multiple types of security policy enforcement—authentication, single sign-on, authorization, credential mapping, device profiling, encryption, tokenization, and so on.
CASB deployment modes are broadly categorized into the following two categories: Inline and Out-of-band.
1. Cloud-native policy engines already support inline CASB capabilities. This provides most of the CASB functionality for an organization as all traffic of all users should be flowing through it before any cloud application is accessed.
2. For traffic that cannot pass through a cloud policy engine or cannot be inspected by this engine, an out-of-band service is required that ensures the security of the data that has been hosted in the externally or internally managed application also known as an out-of-band cloud access security broker (API-CASB). An API-CASB can also help monitor and control flows that may move data from cloud to cloud without any user interaction.
5. Data Privacy and Compliance
When you use Salesforce or Office 365 your data—your content—is stored in the cloud: Salesforce has your records and Office 365 has your email and files, so you need to protect your data. On the other hand, a cloud security service that provides secure access to the internet and SaaS is a security checkpoint function—it should not be storing content at all. Pages visited are inspected but no content is stored. Only logs are stored. It’s almost like an international airport. Your baggage goes through an x-ray machine and, once it is scanned and no threat is identified, your luggage is approved for transportation. No copy of its content is kept. It’s critical that your logs are stored in a location of your choice and obfuscated in a way to satisfy local compliance requirements.
With scores of checkposts around the internet, you would find yourself with a problem if logs were written in every data center, as they would be scattered and may not be protected. While logs do not store content or data, they still have user-identifiable information such as user ID, IP address, or machine identifiers. Ideally, a good cloud security service would not write logs locally but write once to a location of the customer’s choice. An EU company should have the option to store logs in the EU, just as U.S. companies should be able to store logs in the U.S. Large companies may want to store their logs in their own data center.
Some traditional security checkposts do content caching for performance improvement, which means they may store content locally. This increases the data security risk, as the customer data may reside in various data centers. For this reason, a good security service should not cache content, especially since it offers little value in this day of dynamic content.
With proper, customer-defined storage, it would be easier to be compliant with GDPR, but only if the architecture is done right.
There are 111 countries around the world that have passed data privacy laws. The EU General Data Protection Regulation (EU GDPR) is the latest and arguably the most impactful of these. Every organization that collects or even processes data on EU residents will have to prove compliance. This may include employing a special data protection officer (DPO) whose job is to communicate with the data protection supervisor in each country. Noncompliance with GDPR exposes an organization to hefty fines of 20 million euros or four percent of global revenue, whichever is greater.
Benefits of a cloud security platform
The pioneers of this cloud security transformation have all realized these benefits.
Cost savings. Savings are possible just from the reduction in backhaul expense over MPLS circuits. Canceling or avoiding the subscription and maintenance contracts for unified threat management appliances is another major cost savings. The cost of managing hundreds of devices, either by internal teams or an MSSP (Managed Service Security Provider), are also avoided. Factor in the elimination of the need to reinvest in capital equipment every five years or so and the cost arguments get even better.
Enhanced user experience. Going directly to the internet from any location invariably leads to better performance of web applications. The contributors to this book all report positive impacts on the user experience. In the future, as available internet connection speeds grow, especially with the impending move to 5G networks, everyone’s experience will only improve.
Better security. Consistently applied policies and protections no matter the device or location is the secret to good security. A cloud service provider takes advantage of scale to deliver those protections sooner. Millions of endpoints being targeted by threat actors means the cloud service will detect new attacks or malicious URLs early and automatically update the protections for all users.
CISO Journey
AutoNation
Embracing a New Security Architecture for Access to Internet and SaaS Applications
Company: | AutoNation |
Sector: | Retail |
Driver: | Ken Athanasiou |
Role: | CISO |
Revenue: | $22 billion |
Employees: | 28,000 |
Countries: | 1 |
Locations: | 300 |
Company IT Footprint: AutoNation has approximately 28,000 employees. It is the largest seller of cars in the United States. It has 300+ locations with internet points of presence.
“When ransomware attacks happen to other companies, thousands of systems in their environment are crippled, in addition to having serious impacts with having to pay a ransom. When this kind of event hits the news, I get worried calls from executives, and it warms my heart to be able to tell them, ‘We’re fine.’”
Ken Athanasiou, VP and Chief Information Security Officer, AutoNation
AutoNation is a retail organization with 300 locations selling and servicing automobiles. Ken Athanasiou, Chief Information Security Officer at AutoNation, describes how cloud transformation saved AutoNation money while enabling new capabilities. He stresses the importance of timing and careful planning when embarking on a major strategic initiative such as cloud transformation. He further expands on the importance of being adaptable organizationally, and the willingness to make modifications to plans along the way, and approaching it with more of an agile methodology to prevent false starts and failures.
In the words of Ken Athanasiou:
Flexibility, repeatability, and security through cloud transformation
I’ve been at AutoNation for a little over three and a half years, as its first CISO. AutoNation has about 28,000 employees and we are the largest seller of cars in the United States. Prior to joining AutoNation, I was at American Eagle Outfitters as its CISO for about seven years. Previously I was at JPMorgan Chase, as the retail line-of-business information security officer, or BISO, for five years.
Journey begins with a breach
AutoNation experienced a small breach with a third-party vendor in 2014 that exposed about 1,800 customer records. That was enough for our general counsel to start asking questions about ways to improve security. He and a few other executives brought in a couple of different firms to do some assessments and make some recommendations, and one of those recommendations was to build out an independent cyber security team that could help them reduce the risks.
Closing the digital divide
At the same time, there was beginning to be a digital divide, especially for the customers. There is also a digital divide between the brick-and-mortar stores where vehicles are sold and our online presence. The intent is to close that divide and present to our customers a comprehensive user experience, where they can begin the shopping, selection, and credit application process online. They can wander into a store, access what they did online, and move the process forward a few steps; they can then go home, make a few decisions, sleep on it, whatever, and then either complete the purchase process online or come into the store the next day.
“We’re extremely paranoid about how we handle our customers’ data.”
Closing that digital gap and giving our customers the opportunity to participate in a unique buying experience has become a driver for this organization.
Protecting customer data
There are unique security challenges to being an online auto dealer. We take credit applications every day, and credit applications are obviously about the most sensitive personally identifiable information (PII) that you can handle. We also process credit card transactions, so we deal with PCI requirements.
When we have a credit application, we have every piece of information that a bad guy needs to do some pretty robust identity-theft activities, so we’re extremely paranoid about how we handle our customers’ data. A critical element of this process is the ability to protect that type of data, while allowing customers to access it.
Transitioning the CIO
I was hired by a new CIO who had joined the organization just a few months before I did. He was brought in to do some transformational activity and had inherited a significant amount of technology debt within the organization. We made some progress under that CIO and did an enormous amount of work around solving some of that technology debt and getting security in place—and closing some of the most critical gaps that the organization had.
Over the last year and a half or so, we’ve made some dramatic changes within the technology organization. We’ve been able to advance the maturity of the process, get completeness, and instill some robust frameworks.
Backing off on cloud backups
The decision to move to the cloud was made by the technology operations team with our disaster recovery (DR) capability. The misstep we made was to take legacy applications that were heavily dependent upon very large hulking boxes of iron that run very hot and heavy and putting them into a cloud environment without actually refactoring those applications.
The transition didn’t go well. We were about four months late exiting the data center and six months late in actually executing a test against the new cloud DR environment. As predicted, that test failed miserably. We had transactions that had been sub-second go to 60+ seconds from the physical colocation to the cloud environment. It was an abject failure.
One of the first conversations I had with the new technology lead was about fixing our DR environment. We needed to fix it fast, and we had a discussion about what’s the right thing to do. Do we refactor these applications so that they can play well in the cloud? After some discussions with the application development teams, we determined it would take us approximately two to three years to fully refactor the applications, based on the available resources, the workload, and the business requirements.
We made a decision as a team at that stage that the organization could not suffer that type of risk for such an extended period of time. The executives agreed with us and we built a new colo data center. Brand new hardware, all sorts of beautiful, shiny new toys in that data center, and we moved all those applications out of the cloud, back into the traditional data center.
Timing is everything
Although the decision to go to the cloud was a wonderful idea, the problem was that the time frame associated with doing that transition and the requirements of actually executing that transition weren’t fully understood.
As with anything, if you don’t truly understand what you need to do, you’re likely to fail at it. Unless you are adaptable, and you are willing to make modifications to your plans along the way, and approach it with more of an agile methodology, you will fail.
Embracing cloud security
On the client application side, one of the other things that I did when I first got to AutoNation was to install UTM (unified threat management) devices; these are basically SOHO, small home office types of appliances, that combine all the features and functionality of the next-gen firewall on a very small platform.
We had 300+ locations with internet points of presence. The networking team was intending to deploy more than 300 little boxes across the entire country and that’s when I decided it was time for us to learn more about this cool cloud-based network firewall solution that I’d heard of called Zscaler. That’s when I called up Jay and his team and asked to meet with them.
Instead of doing the little boxes of iron across the entire country and rolling trucks all over the place and having to manage that nightmare architecture, we went down the Zscaler route, which was intense. I didn’t sleep for probably six months. I was worried about our exposure. Every time I went to bed, I expected to wake up to a major breach until we got Zscaler rolled out across the environment.
Addressing the security debt
There were quite a few issues that we uncovered as soon as we wrapped Zscaler as a prophylactic around the environment—lack of robust patching and IT hygiene, the ineffectiveness of the McAfee antivirus that we were running, broken update processes across the board, very old systems, middleware that wasn’t being patched.
We looked at various engines that were out there, including hardware based. Three years ago, there really wasn’t any other cloud-based solution that was even comparable to the capabilities that Zscaler had. They were the only true, full-protocol firewall in the cloud. They had the most robust capabilities. Everything else was pretty much just a web proxy. You can pump your traffic through that, but it’s definitely not the same thing.
The rollout decision was a no-brainer
Zscaler was just a completely different architecture, so we made the decision to pilot Zscaler and see how it looked and felt. We rolled out Zscaler to a couple of stores and our corporate headquarters and we let that run for a little bit. Again, the visibility we got into outbound bot traffic, and obvious infections and those sorts of things very quickly upped the urgency of getting a solution deployed across the entire environment.
It became pretty much a no-brainer, and we made the decision to go forward with this even if we had to break a bunch of stuff in order to filter traffic and gain control. We invested capital to drive some maturity into our patching processes and to improve our anti-malware controls.
We took advantage of Zscaler’s anti-malware. When I was first talking with the Zscaler team, I was adamant that I wanted full-blown next-gen firewall capabilities, which would include filtering network-based malware detection and sandboxing.
We are now pretty much fully deployed with Zscaler capabilities. We’re currently not making extensive use of its Zscaler Private Access to access our internal applications, although it’s compelling. We just simply haven’t had the opportunity to really push that out very far. But we’ve got pretty much everything else, like DLP, and all the obvious stuff around the URL filtering. We are now a heavy consumer of Zscaler capabilities and we’ve been very pleased with the controls that we got from them.
Penetration testing has become more difficult, and that’s a good thing
We do aggressive penetration testing using third-party vendors. It’s common for them to become stymied by the Zscaler layer when they’re doing remote testing, because they simply can’t penetrate the malware and sandboxing controls and get anything to work. That’s also a result of the changes that we’ve made around patching. We’re using Tanium for endpoint management across our entire environment, which I am just in love with—it’s a fantastic piece of technology.
So, with all these additional controls in place and obviously driving mature patch processes throughout our environment, our resiliency—our hardness, so to speak—has just gone several levels above where we were previously.
Seeing is believing: The value of reporting
For reporting we don’t often use the stock stuff that comes out of Zscaler, but we do pull numbers from it to include in board presentations. I show the board a bunch of gee-whiz numbers, and these gee-whiz numbers show for the most part how much we’re under attack. The reason I call these gee-whiz numbers is because every single one of these attacks was blocked or prevented by one of the engines that we have in place. This particular set of numbers shows all the attacks or incidents that were blocked or prevented by our cloud-based firewall solution, Zscaler.
It’s more of a validation that this is stuff that we would have to deal with if we didn’t have these controls in place, but the fact is, we do have these controls and, therefore, we wouldn’t consider these incidents or really anything all that important to deal with. We don’t react to them because they’re noise that is filtered out by the engines that we have in place.
The senior executive staff loves the numbers, because they look at them and they go, “Holy smokes, that’s a lot!” Every now and again, we do see spikes in attack activity and I usually end up having to explain the spikes. “What happened there where it jumped up so high?” they’ll ask, and then I’ll usually explain how there is a zero-day exploit or a critical vulnerability that was discovered and we see an enormous amount of traffic attacking that critical vulnerability because it was fresh and new.
“We’re fine”
When ransomware attacks happen to other companies, thousands of systems in their environment are crippled, in addition to having serious impacts with having to pay a ransom. When this kind of event hits the news, I get worried calls from executives, and it warms my heart to be able to tell them, “We’re fine.”
We’ve gotten down to a seven-day patch cycle, and that’s not even a critical or an urgent cycle. If we have a critical patch that needs to be pushed, we can do that in about 24-hours.
Piloting the types of engines that can give visibility into the state of your environment, like the level of botnet traffic and infections, is something that you can then use to drive further activity, spending, and resource implementation.
It’s important to really understand what is going on in your environment in terms of infections and risk levels in order to put something like Zscaler in place. For example, if you have 70 infections, you will find that maybe your patch processes are broken. Then, you could start piloting a couple of engines that look at EDR, response, and software distribution packages. Do a side-by-side comparison, and you’ll find that your Microsoft SCCM product says you’re fully patched—but then when you run something that’s independent of Microsoft against that, it says you’re only patched at about 50%. Well, in that case, you’ve got things in your environment that are missing patches, that are two years old, so something’s wrong there. Again, that would drive further activity to resolve.
Our Office 365 implementation needed more bandwidth at each point of presence
As we made the transition to Office 365, we had to learn how to implement the process. Originally, we were going to have everybody use the portal and not bother putting Office on individual machines. Also, we didn’t have the required bandwidth. It didn’t work, so we had to step back and change up how we do things as a process. Now we’re doing local installs of Office 365, and we’re executing the product differently. It works much better now.
At the time, every one of our locations had from a T-1 up to a multiple T-1 type of MPLS connection back to our data center, so very small pipes for the private circuit back to the data center.
Internet access was also not all that great. You’re talking somewhere around ten megabits per second type of connections to the internet, which, obviously, if you’re not careful with that type of an environment, you will easily clog those pipes and you will have very degraded performance.
Local internet breakouts helped reduce costs
After we got the new technology leadership in place, we renegotiated with our providers and we significantly reduced our network bandwidth cost and jacked up our bandwidth ten-fold. We went from very small MPLS circuits to ten and 20 megabits per second MPLS circuits back to our data center, and 150 megabits per second connections to the internet for the most part. We had very significant increases in performance and capability for internet bandwidth, and again, that was primarily due to a technology gap, lack of planning, and a lack of understanding of the bandwidth requirements involving our most used applications. We still do have MPLS circuits and we have internet circuits. The vast majority of our traffic goes direct to the internet, but we do have internal applications, like our CRM and some other systems, that we just simply backhaul across the MPLS circuit.
Today, we are still using a hybrid network. We have considered doing away with those MPLS circuits and going full internet, maybe using things like a ZPA, but we’ve not made that transition at this point.
We don’t use Zscaler for mobile devices at this point. That’s another one of those things that’s on the list, but we have not actually executed against it. We’re transitioning from Intune over to AirWatch right now for MDM, and once we complete that, we’ll go back and look at what else we could do in that space.
Improving the user experience
One of the other advantages that we’ve gotten out of Zscaler for some of our other cloud-based applications is that the connection speeds through Zscaler are actually pretty robust. This goes back to the peering that Zscaler has done with a lot of the other larger providers out there, like with Microsoft and Office 365. Our number of hops—even though we have to do a tunnel from our external router into the nearest Zscaler cloud, and from Zscaler to Office 365—is only one or two hops, versus going directly from our dealership to the internet; it would actually take longer to get to the service than going through Zscaler.
“When we do acquisitions or divestitures, it’s very easy to enroll a new location in our environment.”
Instead of inducing additional latency because of those pairing connections, we get all our controls in place and we see very minimal latency and, in some cases, our connections are actually even faster.
Taking advantage of cloud capabilities
There are multiple inherent advantages of moving to the cloud. You get better resiliency, you get better scalability, you get a lot of really cool abilities that you can’t get out of a standard colo environment, and as you re-architect your legacy applications, as you build new applications so that they’re actually cloud-focused and can natively take advantage of those capabilities, I expect that we will continue to see more and more of these applications move into this model.
Another advantage is in mergers and acquisitions. For M&A, Zscaler has been a big win for us. When we do acquisitions or divestitures, it’s very easy to enroll a new location in our environment. We don’t have to roll a piece of security hardware out there. For the acquired entity, we simply configure the tunnels for the internet bound traffic to Zscaler and we’re covered.
One of the things that we’ve found to be a little interesting is when we divest a dealership, the acquirer comes in, and they may ask us what we do for our network security. They ask us where our firewall is located. Our response to that has been—we use Zscaler, so you don’t have a physical firewall in there. You’re going to have to figure something out. They don’t like that answer because they’re used to just taking whatever was there and making use of it.
When we do an acquisition, we do more of a rip-and-replace for the technology environment. We may purchase computers with an acquisition, but then we generally will rip them out. We’ll resell them to someone else and put our stuff in.
ARCHITECT Journey
MAN Energy Solutions
Ensuring Both Internal and External Application Access with a Cloud Security Architecture
Company: | MAN Energy Solutions |
Type: | Manufacturing |
Driver: | Tony Fergusson |
Role: | IT Infrastructure Architect |
Revenue: | $4.3 billion |
Employees: | 15,000 |
Countries: | 6 |
Locations: | 100 |
Company IT Footprint: MAN Energy Solutions has 15,000 people in over 100 locations. It has fleets of engines on ships deployed all over the world. Its main offices are in Germany and Denmark. This entity is actually part of the Volkswagen Group, so it is a part of a larger 650,000 person organization.
“To be successful, you really need to sell this concept of cloud transformation—you need to evolve the organizational mindset. This technology is so disruptive that you need the people inside your company onboard.”
Tony Fergusson, IT Infrastructure Architect, MAN Energy Solutions
MAN Energy Solutions is a manufacturer of large engines and turbines with fleets of engines on ships deployed all over the world. Tony Fergusson wanted to move to a model where internal applications were not even visible to attackers. Only authenticated users can see them. He calls this stealth approach the “black cloud,” and MAN Energy Solutions uses the concept to securely access engine sensors on its deployed fleet. He shares how the organization truly discovered the flexibility of cloud-delivered security when it had its first experiences with ransomware—thanks to its cloud security service, this was a non-event.
In the words of Tony Fergusson:
Eight years ago, we started our journey to the cloud at MAN Energy Solutions when I went down the path of creating a forward proxy for access to the internet. I have been in the IT industry for over 20 years. I started with IBM in 1995, so really at the beginning of the internet. I worked at an application service provider (ASP) back in New Zealand, kind of the precursor for what the cloud is today. I have been working in Europe for ten years, mostly in Denmark for MAN Energy Solutions. While a lot of my experience is with Microsoft products like SharePoint and Office 365, I am actually a network architect.
Moving to cloud-based proxies for internet and SaaS applications
Our on-premises proxy gateways needed to be replaced, so I went to the market and discovered Zscaler for secure internet access. At the time, 2011, they were very new. Now I can say we have been a long-term customer.
“We saw that the future was direct access to the internet from everywhere, while at the same time, we needed to inspect all that traffic.”
Back then, we backhauled all internet traffic from every location and had one connection to the internet. We saw that the future was direct access to the internet from everywhere, while at the same time, we needed to inspect all that traffic. As a result, over several years, we went to local breakouts everywhere and inspection of all traffic in the Zscaler cloud security platform. From a security perspective, this model has been a huge success for our company. We discovered the flexibility of cloud-delivered security when we had our first experiences with ransomware. We simply enabled Zscaler sandboxing for all of our users and the problem went away.
Secure access to internal data center applications without VPN
Back in 2014, I had a lot of discussions with Zscaler around what I call “black cloud”; the whole idea was that my applications should not even be visible to attackers. In 2015, we started beta testing Zscaler Private Access (ZPA). We first used it for the many consultants we work with around the world. Our old system of VPNs was very hard to manage. It was difficult to onboard people and get the visibility into what they were accessing.
The first proof-of-concept (PoC) with ZPA was to onboard consultants and it was very successful. We quickly brought all of our consultants onto the platform and we went into full production in 2016, going live in April, the same date that Zscaler officially launched the product. That was when it dawned on me just how powerful this solution was, and we could really do a lot with this technology.
Secure access to engine applications in large ships
The next use case was to start looking at protecting our engines deployed in all of our seagoing vessels. There were only certain people that should be allowed access to the control systems and monitoring software on those vessels so we deployed ZPA.
One of the interesting things about ZPA is that it fulfills my vision of the black cloud. Basically, ZPA acts as a broker for connections. The client software does not know the IP address of the end system. A request is sent and if the requester is properly identified and authorized to get access to the application—or, in this case, the software running on the engine management platform—ZPA initiates the session. It’s like the call-back setting on modems back in the day. The whole platform is based on DNS, so you essentially extract the whole network from the equation. Before ZPA, we were assigning a class-C network space to each engine on every ship. With ZPA, we basically created a namespace routing in between us and the customer. This allowed us to monitor hundreds of ships without looking for a new IP address range.
Now we can secure each connection, which we can define per user per application. We have access control to each engine and we could add strong authentication through identity federation. That led to a thought—why not just replace all of our VPNs with ZPA for all users? After taking that step, it became quite apparent that the next step was to determine what our corporate wide area network was for and if we even needed a corporate network. Why not just put everyone on the internet and secure the access through some sort of software-defined perimeter?
Certainly, we are not there yet but I think within the next few years we will be. Look at WannaCry and NotPetya. Making the corporate campus one big open network is a mistake. In the past, if users wanted access to unsanctioned things we could not support, we just told them no. Now we tell them if you want access to those applications, you have to go through the Zscaler fabric.
We’re starting to migrate applications to AWS, and we have to deploy connectors up there, so we’ll get connectivity for people to access them. I think of it as the company making its own black cloud. I don’t care where the user is or what device they are on. I don’t care whether you are at the office or at home. I just need you to get to the application. If you go through this secure fabric, I know who you are and I know that you actually should have access to this app.
This is the top priority model I have been creating for the company. It is a complete shift in thinking and has taken a couple of years to even solidify it in my head.
Securing the Internet of Things
The biggest problem with IoT is that these devices are generally not patched. They are not complying with standards. They are a security risk. What we are doing is putting this secure fabric between the people who need to access them and the IoT devices themselves.
To accomplish this, we found we needed to create a DNS naming structure. Now our policy is set by DNS names, not IP addresses. I can have an A Record for a device and several different CNAMES, and I can apply policy based on these. The DNS becomes my policy catalog and manager. There is still a lot of thinking we have to do about what this all means.
Better security against ransomware
I remember my management coming to talk to me after NotPetya did so much damage to Maersk. Management was rightfully very concerned. I just looked at them and said, “We’re OK. Everything is closed. Every client is closed. We closed the firewalls to everything. The only way you can get to one of our engines is through Zscaler, through this black cloud. So everything is black. The malware has nowhere to go.”
Cloud security for integrating M&A
Think about how this fabric applies during M&A. We did one acquisition in Zurich and to onboard the new company, I just gave everyone the Zscaler client. As soon as they had Zscaler Internet Access (ZIA), they were at the same security level as we were. Then, when they got Zscaler Private Access (ZPA) they could access our private apps. The whole process took just two weeks.
Advice to infrastructure leaders
To be successful, you really need to sell this concept of cloud transformation—you need to evolve the organizational mindset. This technology is so innovative that you need the people inside your company onboard. I spent a huge amount of time internally evangelizing to my CSO, my management, and everyone on why this is different, and why this works. To further validate, I pointed to them why I was confident that we were protected, and was able to reassure them when they came down to me worried about NotPetya.
Because of this technology, I was able to call a halt to a big 802.1x project we had been working on for Network Access Control (NAC). NAC does nothing for me when I go home or on the road. On the contrary, it can authorize someone infected with NotPetya to get on the network and the next thing you know, everyone is infected.
What not to do
Don’t allow people to build direct IP connectivity into their applications. I wish I had acted earlier to keep that from happening. Get your application developers onboard earlier in the project cycle so they understand the new architecture.
Chapter 4 Takeaways
In a cloud-first world there are no physical boundaries. Controls are enforced by software and networks are taken out of the equation. It is all about users and applications.
Some considerations:
- Castle-and-moat architectures for securing the network are no longer relevant. Provide the right users access to the right applications irrespective of the network, location, or device.
- A built-for-the-cloud security layer is an enabler for cloud transformation. Taking advantage of cloud delivered applications from any device and any location requires distributed security.
- Unlike most security improvements, cloud delivered security enhances user experience.
- Focus on risk. Start with the risks to your data, and evolve to a corporate risk appetite informed by knowledge of threat actors and exposure.
- The burden on IT security teams is lightened, freeing resources to focus on internal security, countering targeted attacks and malicious insiders.
In the next section, we highlight a practical reference architecture for secure cloud transformation and steps taken by one large enterprise organization through its journey.
Next Chapter ›